Ok, time to tell y’all about something new I created recently that should actually help all devs in crypto - Indexer1.
I will try to use simple words to explain complicated things, if you are not dev, I hope you will understand things.
You can’t imagine how much I hate splitting posts into several, so if your zoomer’s adhd can’t read so much: ctrl-A -> ctrl-C -> AI -> ctrl-V -> tl;dr
How blockchains store things?
Blockchain is a tremendous mistake made by humans when they decided to add fees for every transacton and create a mega database for everything.
Imagine if your country (anywhere you live) have a single place where all companies store all their data, it’s never deleted and for no reason everyone keep on using it - this is a blockchain
I will definately create a post with a precise critics of blockchain technology and what to do with it, but what is important to understand is that every database, even Ethereum has a specific way it stores data. This method can not be universal and always has downsides. Blockchains are usually a key-value based storages. This means that you operate within a specifc key that contain value.
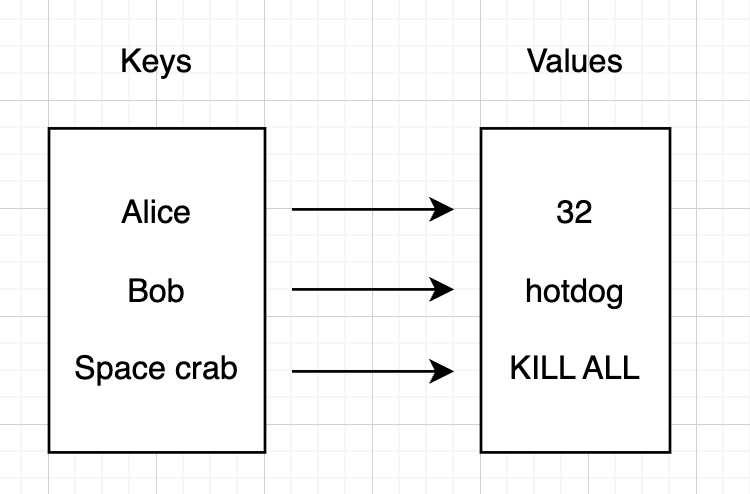
Key value storage
These types of stroages are very efficient when you want to get the data that is stored under a specific keys, however retreiving all keys, or all keys related to a specific category is a very heavy operation.
Good examples are ERC20 tokens: you can easily retreive information about balance of a specific address by calling balanceOf method. However retreiving all token holders is almost imposible and makes no rational sence.
Why? It involves further operation:
Note that address on a blockchain is just a big number
- Ask about balance of address 1
- Ask about balance of address 2
- Repeat for all existing addresses, which is a 20 byte number (2^160, it’s approximately a number with 50 digits)
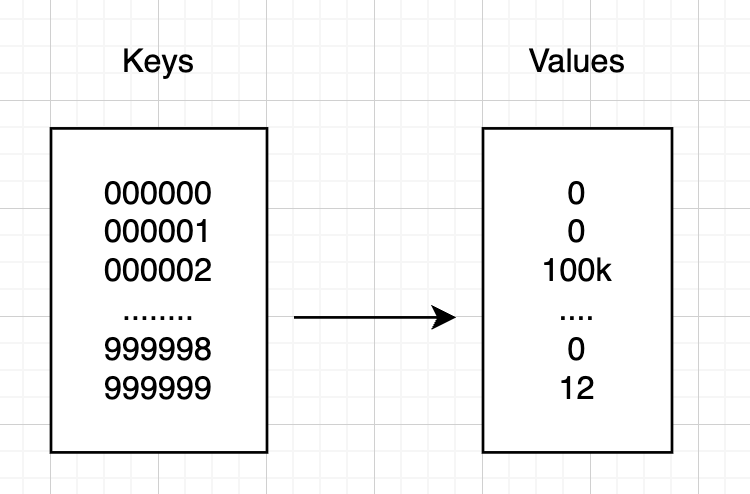
Scheme for example above
And it could make sence, but most of these balances are zero as most of users not exit. Let’s say we have one million token holders, you definately don’t want to wait for a century to know top memecoin holders. We definately want to receive only this “in use” million addresses information rather than receiving everything.

This is only one example that demonstrates one bad case, so?
There is a lot more other information that involves searching through data sequentially (like we do to get all balances) or storing the data that is not directly written in smart contract.
So how do you get all this information?
To actually retreive all this information, developers use magic that they call indexing blockchains. In addition to it’s main storage, blockchain also stores events and does it in a way that there is a sequential access (e.g access one after another).
Ususally developers collect smart contract transactions or events and apply them to their own database that suits their needs. As an example, you can catch all events that represent token transfers and use them to store a SQL table with all balances. As soon as new transfer event is caught, you decrease balance of one address and increase balance of another. This is what indexing is.
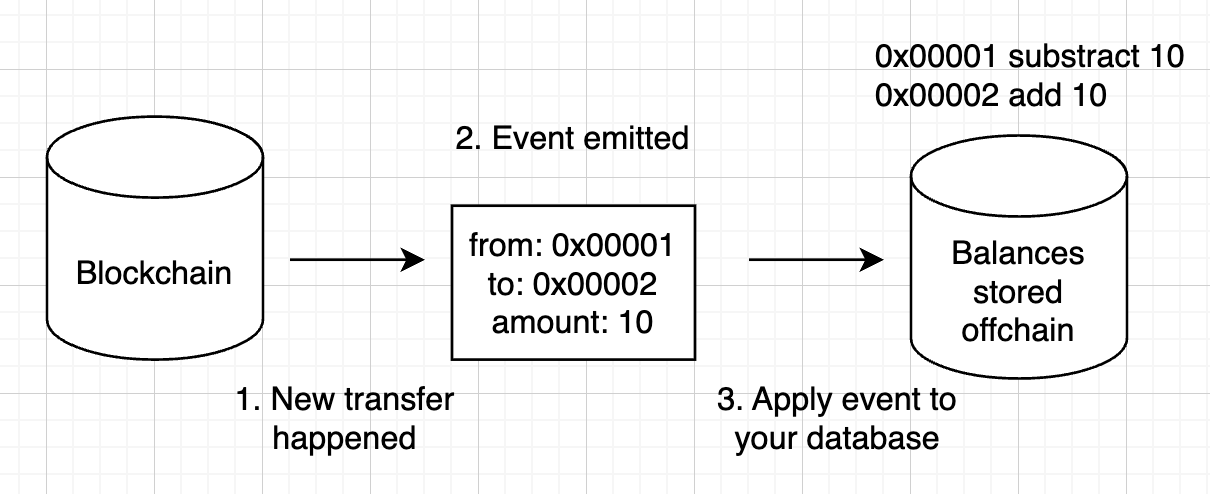
Balances indexing flow
But I still don't get, why it's so important?
- Volumes
- Price charts
- Balances analytics
- Nft collection items list
- And all other unmentioned things.
All of them are only possible to collect by indexing blockchains.
So there are definately tools for this, right?
Unfortunately, since I work as a developer, the only tools I’ve seen and used were my increadably shitty self written solutions.
Literally every company in crypto has it’s own implementation. When it comes to what to use,there are two main categories of devs: those who decided to be happy, and those who really cared abouth their solutions.
Happy guys used The Graph, which basically solves indexing by making you host their solution on their servers and you only write a small javascript module to define how data should be collected. This is a working thing to implement some open source stuff to collect some general purpose data with simple requirements.
However for lots of data requires more flexibility in where and how to store it. Moreover you possibly may want to use other language and something different from GraphQL as API.
There are lots of reasons why The Graph sucks, but lets check how self-made solution usually works.
Most likely you just want to define a method to store all relevant information that you filtered out. For this devs usually write a code that uses someting like EVM RPC method eth_getLogs to retreive events from blockchain within a specified range.
They also store last seen block within every request, so that they won’t receive one event several times even if someting will break on the server side.
This is how it works:
- get events from block 1 to current block (10)
- get events from block 11 to current block (12)
- Something fails and events are not stored!
- All restarts on last seen block - 10
- get events from block 11 to current block (12)
This methodology ensures that blockchain gnomes can’t steal your data everything is consistent.
All cool, seems no problem here
Unfortunately. The problem is in that this same code is written all the time, it’s moved from one project to another by copy pasting and no one still created a good framework to just reuse already existing and well known approaches.
What tf is indexer1?
Indexer1 is a library written in Rust programming language (2025 is here, go learn Rust) to provide out of the box solution for indexing.
The only thing you need to specify there is:
- Database to use (e.g PosrgreSQL, sled or any other)
- Which events to filter out (e.g only uniswap trades)
- How to add events into database (e.g using trade, sum up total volume of every pool)
Then you can create a simple API sever to retreive this data however you want and use anywhere you want.
Indexing strategies
Usually to poll RPC you don’t host your own blockchain node, instead you use RPC providers and pay them per request.
The problem is that if you blindly poll RPC every 10 seconds, you may run into indexing being a very expensive activity.
This is also pretty unnesessary request consuming if there are not so much new events happen on-chain.
- call RPC - nothing
- call RPC - nothing
- call RPC - Yapee, event
- call RPC - nothing
Seem pretty ineficcient, when three out of four events in this example were reundant, however if you don’t poll frequently, then user interface will update very slow and you will get a ticket in discord
For this, Indexer1 allows a more flexible strategy involving websocket subscritptions with HTTP calls commitement. This allows to make it more efficient, by polling within a very rare interval or only when you actually have some unprocessed data, remaining indexing a lot more efficient.
Ok, how can I use it?
If you have any questions or want to contribute - open issue, let’s make this thing better together. Bye